
1️⃣ 기각역(rejection region)
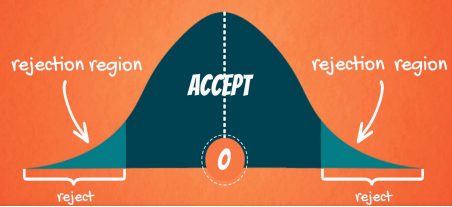
• 귀무가설이 기각되고 대립가설을 채택하는 영역
• 채택한다 ➡ 대안이 가져온 변화나 혁신을 뒷받침할 데이터가 충분하지 않다는 것을 의미
• 기각한다 ➡ 귀무가설이 참을 나타내지 않는다는 통계적 증거가 충분하다는 것을 의미
유의수준 \(\alpha\) (Level of significance)
• 참인 귀무가설을 기각할 확률. 즉 이 오류를 만들 확률
• 주로 사용하는 유의수준 : 0.1, 0.05, 0.001
종류
양측검정(Two-sided/tailed test)
• 양수와 음수 양쪽을 모두 고려하는 가설검정 방법
• 귀무가설이 =이나 !=을 포함할 때 사용
ex. 0.5%의 유의수준이라면 양 끝단에서 각 0.025만큼의 경계를 잡음
단측검정(One-sided/tailed test)
• 어느 한쪽만 고려하는 가설검정 방법
• 귀무가설이 등호가 아닌 <, >등을 포함할 때 사용한다
ex. 0.5%의 유의수준이라면 가설에 따라 한 쪽에서 0.05만큼의 경계를 잡음
2️⃣ p-value
• 관측된 표본 통계량을 고려할 때 귀무 가설을 여전히 기각할 수 있는 가장 작은 유의 수준
• 귀무가설이 옳다고 가정했을 때 관찰한값(ex. 평균값의 차이) 이상으로 극단적인 값이 나올 확률
• 선택한 값보다 p-value가 작으면 귀무가설을 기각한다.
ex. 표본 A와 B의 평균 차이를 알아보려 한다.
이때 귀무가설을 "A와 B의 평균은 같다.''라고 설정한다면,
대립가설은 'A와 B의 평균은 다르다.'가 된다.
A 평균 - B 평균 : 10, p=0.01이라면
귀무가설이 옳은 세계에서 평균값의 차이가 10이상이거나 -10이하가 될 확률은 1%라는 뜻이다.
p-value는 어떻게 사용되는가?
• 대부분의 통계 소프트웨어는 각 검정에 대한 p-값을 계산함
• 연구자는 사후적으로 유의 수준을 결정할 수 있음
• p-값은 일반적으로 점(x.xxx ) 뒤에 3자리로 표시
• p-값이 0.000에 가까울수록 좋음 // p값이 0.000이면 모든 유의수준에서 귀무가설을 기각하겠다는 뜻
결과를 보고하는 다양한 방법
| Accept | Reject |
| X%의 유의성에서 귀무가설을 채택한다 | X%의 유의성에서 귀무가설을 기각한다 |
| X%의 유의성에서 A는 B와 유의한 차이가 없다 | X%의 유의성에서 A는 B와 유의한 차이가 있다 |
| X%의 유의성에서 충분한 통계적 근거가 없다 | X%의 유의성에서 충분한 통계적 근거가 있다 |
| X%의 유의성에서 우리는 귀무가설을 기각할 수 없다 |
X%의 유의성에서 귀무가설을 다시 말할 수 없다. |
[출처]
통계 101 X 데이터 분석, 아베 마사토, 2022
'통계' 카테고리의 다른 글
| 7. 가설검정 (3) 제1종 오류와 제2종 오류 (1) | 2023.11.30 |
|---|---|
| 7. 가설검정 (1) 귀무가설과 대립가설 (0) | 2023.11.23 |
| 6. 추정량과 추정값 (3) 신뢰구간 공식 모음 (모집단 1, 2개일 때/종속, 독립일 때) (0) | 2023.11.16 |
| 6. 추정량과 추정값 (2) 신뢰수준과 신뢰구간 (1) | 2023.11.08 |
| 6. 추정량과 추정값 (1) 추정량(estimator)와 추정값(estimate) (0) | 2023.11.08 |
| 5. 분포 (2) 표본오차, 중심극한정리, 표준오차 (1) | 2023.11.08 |
| 5. 분포 (1) 분포의 정의와 정규분포, 표준정규분포 (3) | 2023.11.08 |
| 4. 중심경향치, 비대칭, 산포도 (4) 공분산(Covariance), 상관계수(Correlation coefficient) (0) | 2023.10.19 |